《数据挖掘》笔记
- CUMT课程笔记
- 2024-01-29
- 53热度
- 0评论
考试题型
八大题:概念、算法描述(4*10)、计算(4*15)
第1讲 绪论
数据挖掘关键技术的定义和区别
关联规则挖掘:从大规模数据中挖掘对象之间的隐含关系,描述在一个事务中物品同时出现的规律的知识模式。
分类:有监督学习方法,利用已知标签的数据集训练,完成对新数据的类别标签预测。
聚类:无监督学习方法,不提供具有标签的数据集,直接以某种聚类规则将数据划分到不同类中。
回归:是一个统计预测模型,用于描述和评估因变量与一个或多个自变量之间的关系
第2讲 认识数据
数据基本特点
分类的(定性)
- 标称属性:标称属性的值提供足够的信息以区分对象,常用众数用作中心化度量。
- 序数属性:提供足够的信息以确定对象的序,但相继值之间的差未知。可以用众数、中位数表示中性趋势,但不能定义均值。
- 二元属性:是一种特殊的标称属性。若两种状态具有同等价值并且具有相同权重,则为对称。若状态结果不是非同等重要,则非对称。
数值的(定量)
- 区间标度属性:用相等的单位尺度度量,值之间的差有意义。
- 比率标度属性:值的差和比例都有意义。
离散和连续属性:具有有限或无限可数个数/属性值为实数。
基本统计方法:中心化趋势度量、离散度度量、分布形状统计量。
数据统计的可视化汇总方法
箱线图:分析多个属性数据的离散度差异性,能显示出最大值、最小值、中位数、上下四分位数。
直方图:分析单个属性在各个区间的变化分布,描述频次分布,有助于了解数据的分布情况,如众数、中位数的大致位置、是否出现缺口或异常值。
散点图:表示因变量随自变量的变化趋势,可用来判断两变量间的相关性。
数据的邻近性度量方法
标称属性:
- 不匹配率:
, 是取值相同状态的属性数。
二值属性:
- 对称的二元属性相异性
,非对称一般忽略00的情况。 - 杰卡德系数:度量非对称的二元相似性,
,忽略00的情况。
序数属性:
做归一化处理,
数值属性:
闵可夫斯基距离可以表示一类的距离,
余弦相似度(计算文档距离):
第3讲 数据预处理
数据清理
- 缺失数据:忽略元组、手动填写缺失值、自动填写(平均值填充或基于贝叶斯、决策树推理)
- 噪声数据:离群点分析、回归
- 数据不一致:替换
数据集成
将来自多个数据源的数据组合成一个连贯的数据源。
对于数据冗余,连续数据可采用相关系数和协方差计算,离散数据可采用卡方检验。
相关系数: 。
。
协方差: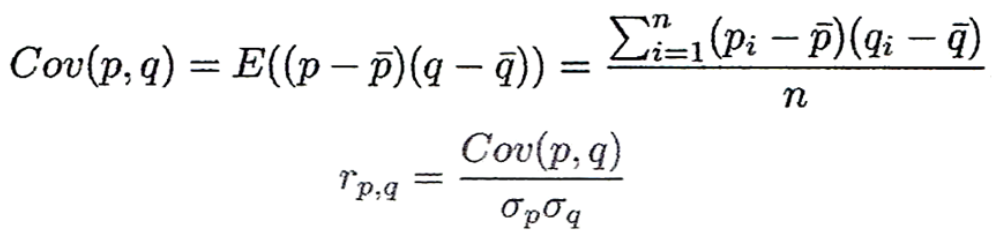 。协方差含义与方差近似,为0代表两属性独立。
。协方差含义与方差近似,为0代表两属性独立。
卡方检验:
数据规约
用较小的数据集替换原数据。
- 降维:主成分分析,挖掘多个属性间的相关关系,将多个具有一定相关性的数据组合成一组无关的综合属性,代替原来的属性。
- 降数据:抽样法。
- 数据压缩
数据规范化和离散化
利用函数映射,为给定属性更换一个新的表示。
数据规范化:
- 最大-最小规范化:进行线性变换,
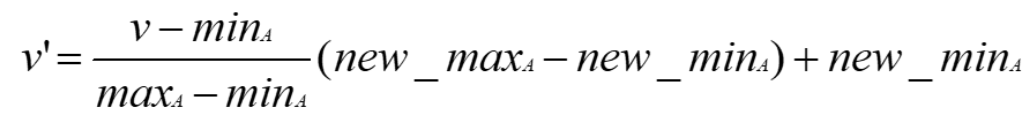
- z-分数规范化:
- 小数点定标规范化:
,j是使Max(|v'|)<1的最小整数。
数据离散化:等宽、等频、聚类
第4讲 关联规则挖掘
基本概念
关联分析用于发现隐藏在大型数据集中令人感兴趣的联系,所发现的模式通常用关联规则或频繁项集的形式表示。关联规则反映一个事物与其它事物之间的相互依存性和关联性。
支持度:包含项集的事务数和总事务数的比值,用于确定项集的频繁程度。
置信度:用于确定Y在包含X的事务中出现的频繁程度。
频繁项集:满足最小支持度阈值的所有项集。
最大频繁项集:它的直接超集都不是频繁的。
关联规则挖掘问题:给定事务的集合T,关联规则挖掘是指找出支持度大于等于minsup并且置信度大于等于minconf的所有规则。大多数算法常将关联规则挖掘任务分解为两个主要的子任务:
- 频繁项集产生:满足最小支持度阈值的所有项集
- 规程产生:提取所有高置信度的规则,这些规则称为强规则
产生频繁项集
Apriori算法
通过连接和剪枝操作,采用自下而上的策略,从频繁1项集开始,逐层搜索频繁项集产生关联规则。采用先验原理——如果一个项集是频繁的,则它的所有非空子集一定是频繁的,如果一个项集是非频繁的,则它的所有超集都是非频繁的。
对项作字典序,如果去掉两个需要连接项集的尾项,剩下的项相同,则可连接,否则则不可连接。
FG-Grown算法
基本思想:只扫描数据库两遍,构造频繁模式树(FP树)。从FP树中挖掘频繁项集,对每个项生成条件模式基,利用条件模式基继续构造FP树,直至结果FP树为空或只含唯一路径,则此路径的每个子路径对应的项集都为频繁项集。
优点:完备,包含了频繁项集挖掘所需的全部信息;紧密,不包含非频繁项,按支持度降序排列,支持度高的在FP树共享机会也高。
产生强规则方法
任务描述:给定频繁项集Y,查找Y的所有非空真子集
针对同一个频繁项集的关联规则,如果规则后件满足子集关系,那么这些规则的置信度间满足反单调性: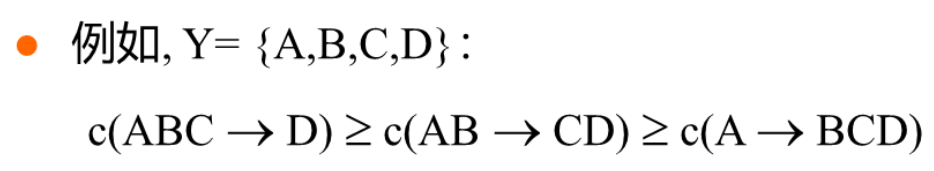
关联分析评估
支持度、置信度、提升度
提升度反映了规则前件(项集A)和后件(项集B)之间的相关性,>1促进,=1独立,<1抑制。
第5讲 聚类基础
聚类概念
分类是通过有标签样本训练分类器,对数据进行标签预测。聚类是不通过训练数据,直接通过观察学习将数据分割为多个簇。
聚类方法有划分方法、层次方法、密度方法、图论聚类方法、网格算法、模型算法等。
划分方法
将有n个对象的数据集D划分为k个簇,满足每个簇中至少包含一个对象,每个对象仅属于一个簇。
基本思想:首先创建一个初始k划分,迭代计算各个簇的聚类中心并依据新的聚类中心调整聚类情况,直至收敛。
代表性算法:k-means(每个簇用簇中对象的均值表示)、k-medoids(每个簇用接近簇中心的一个对象表示)
适用范围:中小规模数据库中的球状聚类,对大规模和处理任意形状的聚类需要进一步扩展。
层次方法
基本思想:对给定数据对象进行层次分解,使用距离矩阵作为聚类标准,不需要输入聚类数目k,但需要终止条件。
典型方法:
-
自底向上(凝聚):初始每个对象一个簇,相继合并两个距离最近(单链接、全链、组平均)的簇。
代表算法:AGNES算法
-
自顶向下(分裂):初始所有对象一个簇,迭代分裂。
代表算法:DIANA算法
优缺点:
- 合并或分裂的决定需要检查和估算大量的对象或簇;
- 一个步骤一旦完成便不能被撤销,优点是避免考虑选择不同组合,计算代价减小,缺点是不能更正错误决定;
- 不具有很好的可伸缩性。
基于密度方法
基本原理:根据密度条件对邻近对象分组形成簇,簇的增长或根据邻域密度,或根据特定的密度函数(只要临近区域密度超过某个阈值,就继续聚类)。
代表算法:DBSCAN算法,抗噪声,能处理各种形状和大小集群。
适用范围:可发现任意形状的聚类;一遍扫描;需要密度参数作为终止条件;可处理噪声数据。
k-means计算原理和过程、特点 //概念
算法描述
- 从数据集中随机取K个样本(也可以是非样本点)作为初始的聚类中心
- 针对数据集中每个样本
,计算它到K个聚类中心的距离并将其分到距离最小的聚类中心对应的类中 - 针对每个类型
,重新计算其聚类中心 - 重复第2.3步骤,直至
,最小化对象到其簇质心的距离的平方和小于特定的阈值
算法复杂度
优缺点
优点:1.聚类时间快;2.当结果簇是密集的,且簇与簇之间区别明显时效果较好;3.相对可扩展和有效,能对大规模数据集进行高效划分。
缺点:1.只适用于数值属性聚类(计算均值有意义);2.事先必须指定分类簇的个数;3.常常终于局部最优;4.对噪声和异常数据敏感;5.初始值不同可能导致结果不同;6.不适合发现非凸面形状的簇。
改进算法
- K-Means++:尽可能选择距离远的点作为初始种子节点。
- K-mode:计算聚类中心时用众数代替平均数。
- K-medoids:为解决对离群点敏感问题。
评价准则
划分方法聚类质量评价准则:最小化E值
第6讲 分类:贝叶斯分类
聚类、分类、回归概念
分类与回归:分类是预测分类(离散、无序)标号数据,回归是建立连续值函数预测模型。
分类与聚类:分类是通过有标签数据学习分类器,聚类是通过观察学习将数据分割为多个簇。
朴素贝叶斯分类原理和计算方法 //计算
计算时通常去掉
第7讲 决策树分类
决策树典型算法:ID3、C4.5、CART
决策树算法优缺点
优点:
- 是一种构建分类模型的非参数方法,不需要昂贵的计算代价,可解释性相对强;
- 是学习离散值函数的典型代表;
- 对于噪声的干扰具有相当好的鲁棒性;
- 冗余属性不会对决策树的准确率造成不利影响。
缺点:
- 天生过拟合;
- 对于叶节点代表的类,不能做出有统计意义的判决;
- 子树可能在决策树中重复多次,使决策树过于复杂;
- 无法学习特征之间的线性关系。
ID3
选择信息增益最大的特征作为节点特征。基于熵的信息增益,会趋向于具有大量不同值的划分如id,解决策略有限制测试条件是二元划分;使用信息增益率。
缺点:倾向于选择取值较多的属性,在有些情况下这类属性可能不好提供太多有价值的信息,只能为离散型属性的数据集构造决策树。
C4.5
优缺点:产生分类规则易于理解,准确率较高;缺点是需要对数据集进行多次顺序扫描和排序,导致算法低效。此外,只适合于能够驻留在内存的数据集,当训练集过大无法在内存容纳时程序无法运行。
CART
选择基尼系数划分选择属性,构建决策树是二叉树。
相比C4.5算法的分类方法,采用了简化的二叉树模型,CART一定是二叉树。
上述构建决策树算法都是选择最优的一个特征来做分类决策,但大多数分类决策应该选择最优的一个特征线性组合,叫做多变量决策树。
过拟合问题
- 预剪枝:如果划分带来的信息增益、Gini指标等低于阈值,或元组数目低于阈值,则停止划分。
- 后剪枝:从完全生长的树中剪去树枝——得到一个逐步修剪树【度量分类器性能】
第8讲 规则和最近邻分类器
基于规则的分类基本原理
规则评估
- 覆盖率:满足规则前件的记录所占比例
- 准确率:满足规则后件的记录所占比例
- Laplace :
,k是类的个数, 是被规则覆盖的正例数,n是被规则覆盖的样例数。可以简单理解为准确率的平滑。
优缺点
优点:表达能力与决策树一样高;容易解释;容易产生;能够快速对新实例分类;性能可与决策树媲美。
缺点:规则库难以维护;规则匹配计算量大;模型缺乏泛化能力。
急切、惰性的区别
急切学习是指在利用算法进行判断之前,利用训练集数据通过训练得到一个目标函数,在需要判断时利用已经训练好的函数进行决策。分为归纳和演绎两步。
惰性学习是把训练数据建模过程推迟到需要对样本进行分类时。例如k-NN算法只是单纯记住所有训练集中的所有样本,在需要进行预测时从自己的训练样本中查找与新样本最相似的样本,即寻找最近邻来获得预测结果。
最近邻分类器的算法原理、计算距离的度量方法
算法原理
从已知类标的实例中,找到距离最近或最相似的实例,并将其类标作为自己的类标。选择k个最相似数据中出现次数最多的分类作为新数据的分类。可以用两种特殊的数据结构提前对数据集进行优化存储,分别为Kd-Tree、Kd-Ball。
- 令k是最近邻数目,D是训练样例的集合
- for 每个测试样例
- 计算z和每个样例
之间的距离d - 选择离z最近的k个训练样例集合
- end for
- 距离加权表决:
第9讲 回归
最小二乘法对线性回归建模
基本思想:保证直接与所有点都接近。若有n个样本点
使上式达到最小值的直线
第10讲 模型评价
分类模型的评价指标
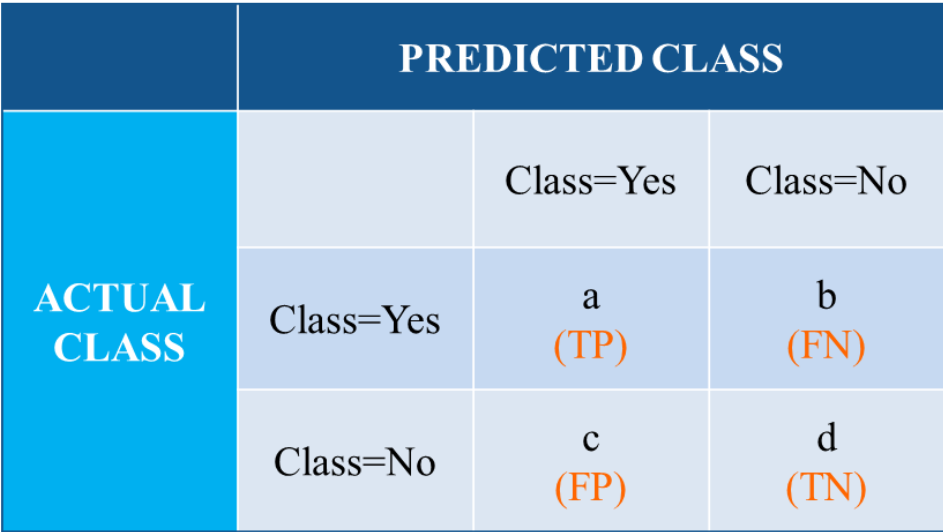
准确率:
精确率:
召回率:
F1值:
ROC曲线:每个点以对应FPR值为纵坐标,以TPR值为横坐标。ROC曲线越靠近左上角,模型准确性越高。
AUC:ROC曲线的面积,衡量二分类模型优劣的以一种评价指标,表示预测的正例排在负例前面的概率。
不平衡问题
- 过采样:通过增加少数类样本的数量来实现样本的平衡,不足在于可能导致模型过拟合,因为一些噪声样本被复制多次。
- 欠采样:通过减少多数类样本的数量来实现样本的平衡,不足在于一些有用负样本可能没有被学习到,导致模型效果不好。
过拟合、欠拟合概念,缓解方法
过拟合
是指在训练数据拟合太好的模型,其泛化误差可能比具有较高训练误差的模型高。原因可能是噪声数据比例过大,或训练数据较少导致模型较复杂。根据奥卡姆剃刀原则,降低泛化误差的缓解方法有:
- 在代价函数后加上正则项;
- 在神经网络中引入dropout机制;
- 交叉验证,在学习到不同复杂度的模型时,选择对验证集有最小预测差的模型;
- 提前停止,用一种迭代截断的方法来防止过拟合;
- 数据集扩充。
欠拟合
是指训练和检验误差都很大,原因是模型尚未学习到数据的真实结构,可能是训练数据过多导致模型较简单。
第11讲 信息推荐算法
协同过滤(相似度)//计算
-
定义项目i和j的相似度
杰卡德系数:
余弦相似度:
,缺点是将缺失分量视为“否定”,解决方法:中心化,每个值不为零的向量值减去均值。 -
选择k个最邻近邻居
-
以加权平均估计评分: